
Alexandra Ballow
Senior Undergraduate Mathematics and Physics double major at Youngstown State University

Pressure sensors are used for a vast range of applications, such as in small electronics, automobiles, and in the future as bio-skin and during surgeries. Because of the multitude of applications, there is considerable interest in improving these nanosensors. However, these changes often cause small pressure sensors to have lifetimes of only a few hours. Recently Dolleman et al. have designed a new version of these sensors, which is expected to be stable over a longer lifespan. We create a model of an open squeeze-film pressure sensor. This model will enable simulations of these devices, aiding in both device design and interpretation of measurements.
This project was coded within the framework of AMReX(developed by the CCSE group at LBNL). This framework in addition to the direct mentorship of many members of the group allowed me to take lead on this project. Some of the coding was above my ability, to enable me to continue working members of the CCSE helped code the hardest parts.

This study focuses on developing methodologies to minimize the effects of incomplete data. Specifically, it hopes to reduced the noise and bias caused in categorical sequence data by data gaps. Some strategies investigated include choosing a substitution “cost” to replace missing values and deleting the missing values at the end of a sequence. Cluster validity metrics are used to determine the accuracy of the unsupervised clustering algorithms and t-SNE is employed to visualize clusters and age biases. It became clear that deleting missing values provided the best results, but all data sets are different. Thus this study recommends employing the studied procedures before conducting analysis on longitudinal sequence data to ensure the results are unbiased. After these tests optimize the data, clustering is conducted to understand the correlation between a person’s state in life and their travel.
After initial algorithm testing mentors gave direction, but I took ownership of the project.

The treatment of infections is an important focus for many medical professionals and mathematicians. Innate immunity is the body’s first defense against invading pathogens. However, if an infection occurs, the immune system’s main way of destroying invading pathogens is by using phagocytes to engulf and kill the microorganisms. In the process of destroying the microorganisms, neutrophils arrive in what is called the inflammatory response. Then, through extravasation, neutrophils migrate through the blood vessel wall into the infected tissue. Neutrophils then bind bacteria, engulf, and destroy them. Finally, a neutrophil dies by apoptosis and leave pus at the infected site. The purpose of our study is to create an interactive and mathematical simulation of a various number of infections, using cellular automata modeling.
The project idea was provided by our mentor, the rest has been me and another student. She still provides occasional guidance, but follows a hands off approach.
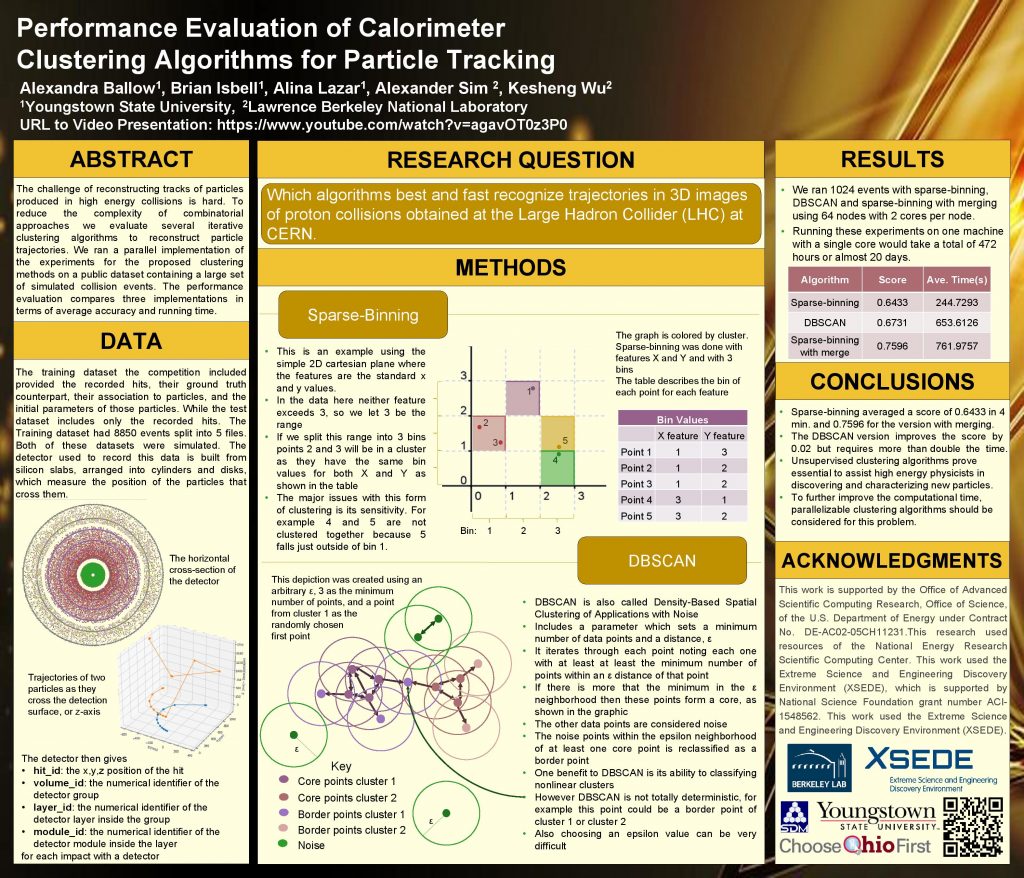
The challenge of reconstructing tracks of particles produced in high energy collisions is mainly computational. With the ever-growing data from scientific experiments, it is imperative to have automatic ways to analyze that data. Combinatorics approaches currently used to track particles will become inadequate as the number of simultaneous collisions will increase in the next phase of the High Luminosity Large Hadron Collider (HLLHC). To reduce the complexity of combinatorial approaches we evaluate several iterative algorithms based on clustering algorithms to reconstruct particle trajectories. Specifically, we analyze clustering algorithms based on sparse binning and DBSCAN. The sparse binning algorithm separates the detector space into bins before performing the grouping step. This idea speeds up the algorithm but affects the accuracy. We ran a high performance computing implementation of the proposed clustering approaches on a public dataset containing a large set of simulated collision events. The performance evaluation is done for three different clustering implementations in terms of average accuracy and computational speed.
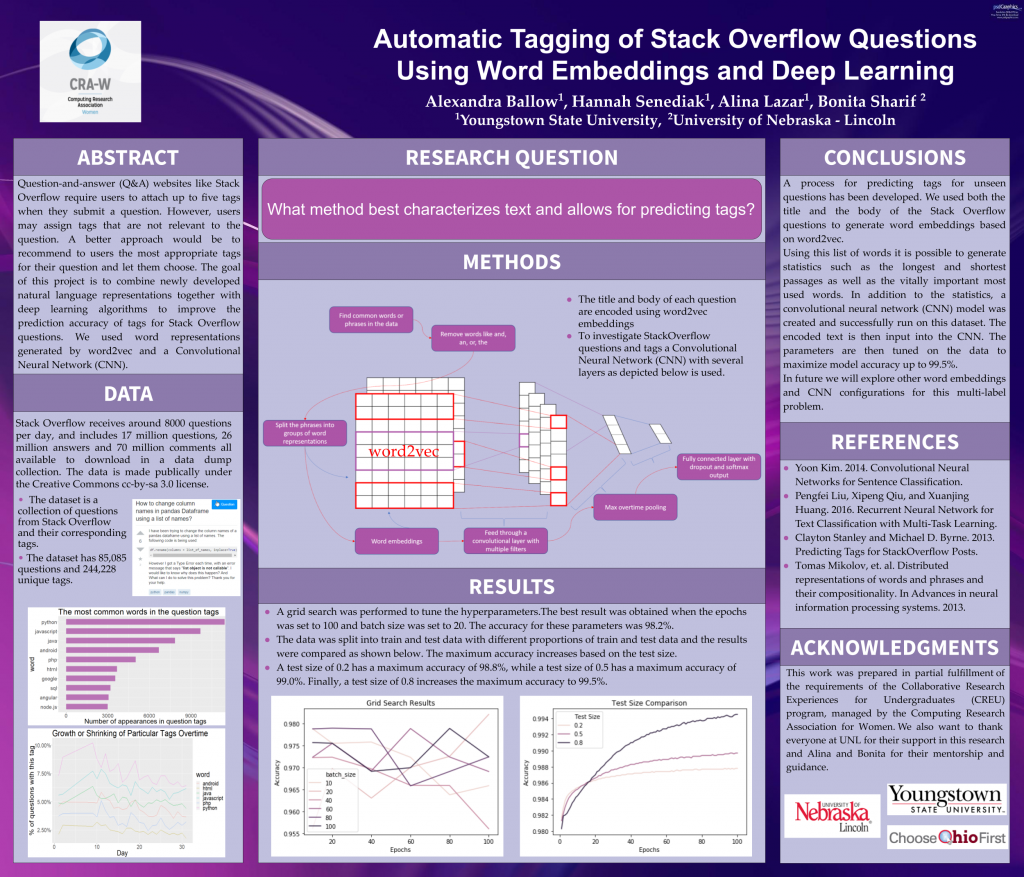
Question-and-answer (QA) websites like Stack Overflow require users to attach up to five tags when they submit a question. How-ever, users may assign tags that are not relevant to the question.A better approach would be to recommend to users the most appropriate tags for their question and let them choose. The goal of this project is to combine newly developed natural language representations together with deep learning algorithms to improve the prediction accuracy of tags for Stack Overflow questions. We used word representations generated by word2vec and a Convolutional Neural Network (CNN).
The initial project idea was the work of our mentors. The rest of the project work from initial research to completion of posters was split between myself and another student, Hannah Senediak. Hannah focused mostly on testing various internet algorithms and traveling to give presentations while I found statistics of the dataset, layered the algorithms Hannah was testing, and creating posters.